 LASER: Layer SElective Rank-Reduction
LASER: Layer SElective Rank-Reduction
LASER (LAyer SElective Rank-Reduction) is an intervention strategy for Large Language Models that was introduced in the Paper The Truth Is In There: Improving Reasoning in Language Models with Layer-Selective Rank Reduction, (Sharma, Ash, and Misra, arXiv 2023). As the name suggests, LASER replaces selected weight matrices in an LLM with their low-rank approximation (which can be thought of as a way to compress information). The key surprising finding of the paper was that given a task, if we do LASER interventions properly, these reductions improve the performance of the LLM on that task, at times by 20-30 percentage points. Figure below visualizes LASER intervention in an LLM.
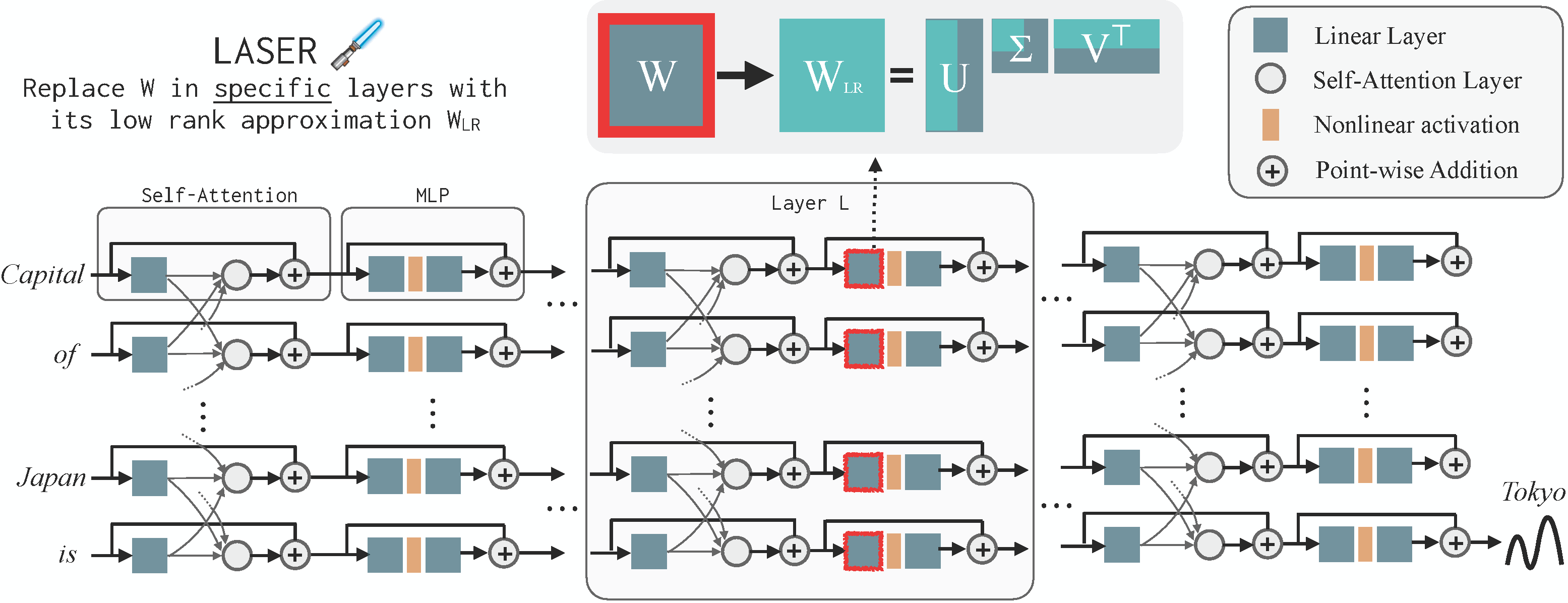
The findings also show that improvements typically come from performing LASER in the MLP weight matrices in the latter half of the LLM. These results also didnt seem restricted to just LLM and were observed in Decision Transformers in an RL task.
There are lots of open questions in this space and several possible ways to extend these results. A goal of this webpage is to contain a leaderboard with results on various benchmarks, and LLMs along with evaluating different modifications to LASER. The code is open source (MIT license) and we welcome contributions. The GitHub Page contains instructions for running LASER. We also provide a short installation snippet below:
# Clone the Laser code
git clone https://github.com/pratyushasharma/laser.git
# (Optional) create a conda environment.
conda create -n Laser python=3.8 -y
conda activate Laser
# Install Requirements
python3 -m pip install -r requirements.txt
# Run a sample experiment (E.g., try GPTJ on Bios Gender dataset with a chosen LASER intervention)
python3 intervention_llama2_bios.py --lname fc_in --rate 9.9 --lnum 26
Does LASER require training? To perform a single LASER intervention, you do need to select 3 scalar hyperparameters: the layer to edit, the parameter type to edit and the amount of reduction to do. We typically find that doing significant reduction on the later layers (often times the last) of MLP parameters often works. Most recently, we found that doing this on Phi-1.5 LLM on the CounterFact dataset, immediately gave a 5-6 percentage point improvement without any fine-tuning. However, this is not always the case. See Table 3 for list of optimal hyperparameters.
Can LASER reduce memory cost? LASER can indeed reduce memory footprint. Given a nxn matrix whose rank is reduced to 1% of maximum rank, we get a memory reduction down to roughly 2% of the orignal. However, currently the code doesnt support this memory reduction feature. We aim to support it soon.
Can LASER be applied to a (some LLM name) LLM? One can apply LASER to any LLM. We will release a tutorial soon to show how to do so. In fact, it can also be applied to other transformer architectures, and in principle, any deep neural network. Our code, however, currently only supports Llama2, GPT-J, Phi-1.5, Decision Transformer and Roberta. If your LLM is on HuggingFace, then it should be very easy to modify the code to apply LASER to the LLM. Finally, while we observed improvements with LASER across several benchmarks and LLMs, there is currently no mathematical guarantee that this will always happen. We encourage you try and paste results and add to the community knowledge (see the next question).
I have a new result/found a way to improve LASER We welcome such contributions. Please send us either an email or contribute to Github discussion and we will add the results to the leaderboard below unless you tell us not to.


